Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
Loading...
USE ApDB;
DROP TABLE IF EXISTS Boeken;USE ApDB;
DROP TABLE IF EXISTS Boeken;
CREATE TABLE Boeken(
Id INT AUTO_INCREMENT PRIMARY KEY,
Voornaam varchar(50) char set utf8mb4,
Familienaam varchar(80) char set utf8mb4,
Titel varchar(255) char set utf8mb4,
Uitgeverij varchar(255) char set utf8mb4,
Stad varchar(50) char set utf8mb4,
Verschijningsdatum varchar(4),
Herdruk varchar(4),
Commentaar varchar(2000) char set utf8mb4,
Categorie varchar(120) char set utf8mb4
);USE ApDB;
CREATE TABLE Kledingstukken (
Nummer INT NOT NULL,
Soort ENUM('polo','broek','trui'),
Formaat ENUM('small','medium','large')
);USE ApDB;
INSERT INTO Kledingstukken
VALUES
(1, 'polo', 'small'),
(2, 'polo', 'medium'),
(3, 'polo', 'large'),
(4, 'broek', 'small'),
(5, 'broek', 'medium'),
(6, 'broek', 'large'),
(7, 'trui', 'small'),
(8, 'trui', 'medium'),
(9, 'trui', 'large');USE ApDB;
INSERT INTO Kledingstukken
VALUES
(10,'hemd','extra large');USE ApDB;
SELECT *
FROM Kledingstukken
ORDER BY Formaat;ALTER TABLE Boeken ADD COLUMN ISBN VARCHAR(25) DEFAULT ("ABC123");CREATE TABLE Boeken (
Id INT AUTO_INCREMENT PRIMARY KEY,
Personen_Id INT, -- = persoon die bij dit boek hoort
CONSTRAINT fk_Boeken_Personen FOREIGN KEY (Personen_Id)
REFERENCES Personen(Id)
);ALTER TABLE Boeken
ADD COLUMN Personen_Id INT, -- = persoon die bij dit boek hoort
ADD CONSTRAINT fk_Boeken_Personen
FOREIGN KEY (Personen_Id)
REFERENCES Personen(Id);Exhalation is het lievelingsboek van Vincent
The Tempest is het lievelingsboek van Michiel
Never Let Me Go is het lievelingsboek van Esther



ALTER TABLECREATE DATABASE ApDB;USE ApDB;CREATE TABLE Personen(Voornaam VARCHAR(50), Familienaam VARCHAR(50), Geboortejaar INT);CREATE DATABASE IF NOT EXISTS `ApDB` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `ApDB`;
-- MySQL dump 10.13 Distrib 5.7.28, for Linux (x86_64)
--
-- Host: localhost Database: ApDB
-- ------------------------------------------------------
-- Server version 8.0.17
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!40101 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `Boeken`
--
DROP TABLE IF EXISTS `Boeken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `Boeken` (
`Voornaam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`Familienaam` varchar(200) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`Titel` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`Stad` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`Verschijningsjaar` varchar(4) DEFAULT NULL,
`Uitgeverij` varchar(80) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`Herdruk` varchar(4) DEFAULT NULL,
`Commentaar` varchar(150) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL,
`Categorie` varchar(120) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`IngevoegdDoor` varchar(255) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Boeken`
--
LOCK TABLES `Boeken` WRITE;
/*!40000 ALTER TABLE `Boeken` DISABLE KEYS */;
INSERT INTO `Boeken` VALUES ('Aurelius','Augustinus',NULL,NULL,NULL,NULL,NULL,NULL,'Metafysica',NULL),('Diderik','Batens','Logicaboek','','1999','','','','Metafysica',''),('Stephen','Hawking','The Nature of Space and Time',NULL,NULL,NULL,NULL,NULL,'Wiskunde',NULL),('Stephen','Hawking','Antwoorden op de grote vragen',NULL,NULL,NULL,NULL,NULL,'Filosofie',NULL),('William','Dunham','Journey through Genius: The Great Theorems of Mathematics',NULL,NULL,NULL,NULL,NULL,'Wiskunde',NULL),('William','Dunham','Euler: The Master of Us All',NULL,NULL,NULL,NULL,NULL,'Geschiedenis',NULL),('Evert Willem','Beth','Mathematical Thought',NULL,NULL,NULL,NULL,NULL,'Filosofie',NULL),('Jef','B','Het Boek',NULL,NULL,NULL,NULL,NULL,'Filosofie',NULL),('Mathijs','Degrote','Leren werken met SQL',NULL,NULL,NULL,NULL,NULL,'Informatica',NULL);
/*!40000 ALTER TABLE `Boeken` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Honden`
--
DROP TABLE IF EXISTS `Honden`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `Honden` (
`Naam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`Leeftijd` tinyint(4) NOT NULL,
`Geslacht` enum('mannelijk','vrouwelijk') DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Honden`
--
LOCK TABLES `Honden` WRITE;
/*!40000 ALTER TABLE `Honden` DISABLE KEYS */;
INSERT INTO `Honden` VALUES ('Rose',1,'vrouwelijk'),('Lacy',7,'vrouwelijk'),('Phoebe',4,'vrouwelijk'),('Camilla',14,'vrouwelijk'),('Betsy',7,'vrouwelijk'),('Lena',8,'vrouwelijk'),('Ella',8,'vrouwelijk'),('Samantha',15,'vrouwelijk'),('Sophia',7,'vrouwelijk'),('Abby',4,'vrouwelijk'),('Lily',10,'vrouwelijk'),('Biscuit',11,'vrouwelijk'),('Nori',8,'vrouwelijk'),('Sam',5,'vrouwelijk'),('Mika',9,'vrouwelijk'),('Baby',10,'vrouwelijk'),('Blondie',14,'vrouwelijk'),('Leia',10,'vrouwelijk'),('Mackenzie',10,'vrouwelijk'),('Trixie',11,'vrouwelijk'),('Hannah',9,'vrouwelijk'),('Kallie',5,'vrouwelijk'),('Maya',14,'vrouwelijk'),('Inez',15,'vrouwelijk'),('Gemma',8,'vrouwelijk'),('Priscilla',9,'vrouwelijk'),('Zoe',8,'vrouwelijk'),('Camilla',1,'vrouwelijk'),('Fiona',9,'vrouwelijk'),('Marley',11,'vrouwelijk'),('Betsy',12,'vrouwelijk'),('Bailey',8,'vrouwelijk'),('Gia',5,'vrouwelijk'),('Peanut',4,'vrouwelijk'),('Fern',4,'vrouwelijk'),('Tootsie',13,'vrouwelijk'),('Summer',11,'vrouwelijk'),('Gidget',3,'vrouwelijk'),('Brandy',1,'vrouwelijk'),('Peaches',1,'vrouwelijk'),('Sophie',11,'vrouwelijk'),('Cookie',14,'vrouwelijk'),('Ivy',1,'vrouwelijk'),('Mackenzie',10,'vrouwelijk'),('Sammie',9,'vrouwelijk'),('Sandy',8,'vrouwelijk'),('Callie',12,'vrouwelijk'),('Samantha',10,'vrouwelijk'),('Lola',2,'vrouwelijk'),('Angel',14,'vrouwelijk'),('Edie',12,'vrouwelijk'),('Diamond',5,'vrouwelijk'),('Bonnie',1,'vrouwelijk'),('Cinnamon',8,'vrouwelijk'),('Ella',12,'vrouwelijk'),('Brooklyn',14,'vrouwelijk'),('Miley',7,'vrouwelijk'),('Pebbles',5,'vrouwelijk'),('Hazel',3,'vrouwelijk'),('Peaches',7,'vrouwelijk'),('Bean',6,'vrouwelijk'),('Bianca',10,'vrouwelijk'),('Brandy',9,'vrouwelijk'),('Cleo',8,'vrouwelijk'),('Sam',9,'vrouwelijk'),('Precious',2,'vrouwelijk'),('Star',13,'vrouwelijk'),('Tessa',15,'vrouwelijk'),('Callie',6,'vrouwelijk'),('Daisy',15,'vrouwelijk'),('Darlene',9,'vrouwelijk'),('Madison',5,'vrouwelijk'),('Biscuit',4,'vrouwelijk'),('Lacy',8,'vrouwelijk'),('Destiny',4,'vrouwelijk'),('Olivia',6,'vrouwelijk'),('Allie',15,'vrouwelijk'),('Khloe',13,'vrouwelijk'),('Dolly',14,'vrouwelijk'),('Bonnie',6,'vrouwelijk'),('Blossom',7,'vrouwelijk'),('Jenna',14,'vrouwelijk'),('Violet',12,'vrouwelijk'),('Bean',13,'vrouwelijk'),('Anna',12,'vrouwelijk'),('Betty',12,'vrouwelijk'),('Destiny',3,'vrouwelijk'),('Nina',3,'vrouwelijk'),('Tilly',14,'vrouwelijk'),('Dana',10,'vrouwelijk'),('Ruby',14,'vrouwelijk'),('Fiona',3,'vrouwelijk'),('Brutus',8,'mannelijk'),('Nero',5,'mannelijk'),('Otto',13,'mannelijk'),('Rascal',9,'mannelijk'),('Kane',1,'mannelijk'),('Odie',9,'mannelijk'),('Ralph',9,'mannelijk'),('Tank',14,'mannelijk'),('Taz',2,'mannelijk'),('Kobe',5,'mannelijk'),('Dodge',4,'mannelijk'),('Aries',11,'mannelijk'),('Ned',11,'mannelijk'),('Alex',9,'mannelijk'),('Bo',10,'mannelijk'),('Eli',5,'mannelijk'),('Porter',2,'mannelijk'),('Duke',6,'mannelijk'),('Carter',13,'mannelijk'),('Casper',14,'mannelijk'),('Brutus',2,'mannelijk'),('Buddy',12,'mannelijk'),('Barkley',9,'mannelijk'),('Theo',5,'mannelijk'),('Maverick',12,'mannelijk'),('Buddy',9,'mannelijk'),('Taz',5,'mannelijk'),('Harvey',11,'mannelijk'),('Scout',5,'mannelijk'),('Rudy',13,'mannelijk'),('Trapper',15,'mannelijk'),('Buster',10,'mannelijk'),('Rocco',4,'mannelijk'),('Vinnie',1,'mannelijk'),('Murphy',13,'mannelijk'),('George',9,'mannelijk'),('Milo',11,'mannelijk'),('Kobe',2,'mannelijk'),('AJ',3,'mannelijk'),('Cash',11,'mannelijk'),('Eli',6,'mannelijk'),('Dane',9,'mannelijk'),('Theo',13,'mannelijk'),('Cash',7,'mannelijk'),('Nelson',3,'mannelijk'),('Luke',10,'mannelijk'),('Harvey',4,'mannelijk'),('Riley',6,'mannelijk'),('Tyson',9,'mannelijk'),('Gage',5,'mannelijk'),('Iggy',2,'mannelijk'),('Marley',7,'mannelijk'),('Fritz',15,'mannelijk'),('Bailey',14,'mannelijk'),('Porter',3,'mannelijk'),('King',10,'mannelijk'),('Snoopy',10,'mannelijk'),('Lewis',15,'mannelijk'),('Levi',1,'mannelijk'),('Leo',10,'mannelijk'),('Vince',2,'mannelijk'),('Trapper',13,'mannelijk'),('Kobe',11,'mannelijk'),('Simba',11,'mannelijk'),('Zeus',3,'mannelijk'),('Flash',15,'mannelijk'),('Watson',6,'mannelijk'),('Benji',3,'mannelijk'),('Frankie',15,'mannelijk'),('Dane',3,'mannelijk'),('Finn',1,'mannelijk'),('Coco',8,'mannelijk'),('Bailey',11,'mannelijk'),('Storm',11,'mannelijk'),('Griffin',2,'mannelijk'),('Zeus',13,'mannelijk'),('Boomer',15,'mannelijk');
/*!40000 ALTER TABLE `Honden` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Kledingstukken`
--
DROP TABLE IF EXISTS `Kledingstukken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!40101 SET character_set_client = utf8 */;
CREATE TABLE `Kledingstukken` (
`Nummer` int(11) NOT NULL,
`Type` enum('polo','broek','trui') DEFAULT NULL,
`Formaat` enum('small','medium','large') DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Kledingstukken`
--
LOCK TABLES `Kledingstukken` WRITE;
/*!40000 ALTER TABLE `Kledingstukken` DISABLE KEYS */;
INSERT INTO `Kledingstukken` VALUES (1,'polo','small'),(2,'polo','medium'),(3,'polo','large'),(4,'broek','small'),(5,'broek','medium'),(6,'broek','large'),(7,'trui','small'),(8,'trui','medium'),(9,'trui','large');
/*!40000 ALTER TABLE `Kledingstukken` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2019-11-26 9:41:44ALTER TABLE Boeken ADD Id INT AUTO_INCREMENT PRIMARY KEY;SHOW COLUMNS FROM Boeken;USE ApDB;
CREATE TABLE Personen (
Id INT AUTO_INCREMENT PRIMARY KEY,
Voornaam varchar(255) char set utf8mb4 NOT NULL,
Familienaam varchar(255) char set utf8mb4,
Leeftijd int
);ALTER TABLE Boeken AUTO_INCREMENT = 5;USE ApDB;
ALTER TABLE Boeken DROP PRIMARY KEY;USE ApDB;
SELECT * FROM Boeken;USE ApDB;
SELECT Voornaam, Titel FROM Boeken;SELECT Boeken.Voornaam, Boeken.Titel FROM Boeken;USE ApDB;
SELECT * FROM Boeken ORDER BY Titel;USE ApDB;
SELECT * FROM Boeken ORDER BY Voornaam, Titel;USE ApDB;
SELECT * FROM Boeken ORDER BY 1, 2;SETReleasedatumUSE ApDB;
SET SQL_SAFE_UPDATES = 0;
ALTER TABLE Leden
ADD COLUMN Taken_Id INT, -- d.w.z. de taak die bij dit lid hoort
ADD CONSTRAINT fk_Leden_Taken
FOREIGN KEY (Taken_Id) -- dit is de kolom (uit de eigen tabel) waarmee we verwijzen
REFERENCES Taken(Id); -- dit is hetgeen waar we naar verwijzen (kolom andere tabel)
UPDATE Leden
SET Taken_Id = 2
WHERE Naam = 'Yannick';
UPDATE Leden
SET Taken_Id = 1
WHERE Naam = 'Bavo';
UPDATE Leden
SET Taken_Id = 3
WHERE Naam = 'Max';
ALTER TABLE Leden
CHANGE Taken_Id Taken_Id INT NOT NULL;
SET SQL_SAFE_UPDATES = 1;@NintendoEurope: Don't forget -- Nintendo Labo: VR Kit launches 12/04!
@NintendoEurope: Splat it out in the #Splatoon2 EU Community Cup 5 this Sunday!
@NintendoEurope: Crikey! Keep an eye out for cardboard crocs and other crafty wildlife on this jungle train ride! #Yoshi
@Xbox: You had a lot to say about #MetroExodus. Check out our favorite 5-word reviews.
@Xbox: It's a perfect day for some mayhem.
@Xbox: Drift all over N. Sanity Beach and beyond in Crash Team Racing Nitro-Fueled.('Don''t forget -- Nintendo Labo: VR Kit launches 12/04!',1),
('Splat it out in the #Splatoon2 EU Community Cup 5 this Sunday!',1),
('Crikey! Keep an eye out for cardboard crocs and other crafty wildlife on this jungle train ride! #Yoshi',1),
('You had a lot to say about #MetroExodus. Check out our favorite 5-word reviews.',2),
('It''s a perfect day for some mayhem.',2),
('Drift all over N. Sanity Beach and beyond in Crash Team Racing Nitro-Fueled.',2)USE ApDB;
SELECT Handle, Bericht
FROM Users
INNER JOIN Tweets
ON Users_Id = Users.Id;CREATE TABLE Platformen(Naam varchar(50) CHARSET utf8mb4 NOT NULL, Id INT AUTO_INCREMENT PRIMARY KEY);
CREATE TABLE Games(Titel varchar(50) CHARSET utf8mb4 NOT NULL, Id int auto_increment primary key);
CREATE TABLE Releases(Games_Id INT NOT NULL,
Platformen_Id INT NOT NULL,
CONSTRAINT fk_Releases_Games FOREIGN KEY (Games_Id) REFERENCES Games(Id),
CONSTRAINT fk_Releases_Platformen FOREIGN KEY (Platformen_Id) REFERENCES Platformen(Id));INSERT INTO Platformen(Naam)
VALUES
('PS4'),
('Xbox One'),
('Windows'),
('Nintendo Switch');
INSERT INTO Games(Titel)
Values
('Anthem'),
('Sekiro: Shadows Die Twice'),
('Devil May Cry 5'),
('Mega Man 11');
-- je zou dit typisch niet met de sleutels doen
-- hier nemen we echter over uit de cursus
INSERT INTO Releases(Games_Id,Platformen_Id)
values
(1,1),
(1,2),
(1,3),
(2,1),
(2,2),
(2,3),
(3,1),
(3,2),
(4,1),
(4,2),
(4,3),
(4,4);USE ApDB;
SELECT Games.Titel, Platformen.Naam
FROM Releases
INNER JOIN Platformen ON Releases.Platformen_Id = Platformen.Id
INNER JOIN Games ON Releases.Games_Id = Games.IdUSE ApDB;
ALTER TABLE Boeken DROP COLUMN Voornaam;-- herstel de kolom
-- deze mag tot 150 (mogelijk internationale) karakters bevatten
USE ApDB;
ALTER TABLE Boeken ADD COLUMN Commentaar VARCHAR(150) CHAR SET utf8mb4;ALTER TABLE TableName CHANGE OldColumnName NewColumnName NewColumnType;USE ApDB;
set sql_safe_updates = 0;
UPDATE Boeken SET Familienaam = "Niet gekend";
set sql_safe_updates = 1;USE ApDB;
ALTER TABLE Boeken CHANGE Familienaam Familienaam VARCHAR(200) CHAR SET utf8mb4 NOT NULL;RENAME TABLE `OldTableName` TO `NewTableName`;USE ApDB;
RENAME TABLE `Boeken` TO `MijnBoeken`;Geen leerstof en/of in opbouw
USE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
-- deze vergelijking levert TRUE of FALSE of NULL op
WHERE Familienaam = 'Augustinus';USE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
WHERE Voornaam = 'Diderik';USE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
WHERE Titel = NULL;USE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
-- <> betekent het omgekeerde van =
WHERE Titel <> NULL;USE ApDB;
SELECT DISTINCT Naam
FROM Honden;USE ApDB;
SELECT *
FROM Honden
WHERE Leeftijd >= 1 AND Leeftijd <= 2;USE ApDB;
SELECT *
FROM Honden
WHERE Leeftijd BETWEEN 1 AND 2;USE ApDB;
SELECT Geslacht
FROM Honden
GROUP BY Geslacht
WHERE AVG(Leeftijd) > 4;USE ApDB;
SELECT DISTINCT Naam, Geslacht
FROM Honden;ANDORNOTXORUSE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
WHERE Familienaam LIKE 'b%';INSERT INTO Boeken ( Voornaam, Titel )
VALUES
('Gerard', 'Heideggers vraag naar de techniek'),
('Diderik', 'Logicaboek');"WAF!"SELECT 'c' BETWEEN 'a' AND 'e';SELECT 'C' COLLATE utf8mb4_0900_bin BETWEEN 'a' AND 'e';USE ApDB;
SET SQL_SAFE_UPDATES = 0;
UPDATE Boeken SET Categorie = 'Metafysica';
SET SQL_SAFE_UPDATES = 1;USE ApDB;
UPDATE Boeken
SET Categorie = 'Wetenschap',
Titel = 'Een boek';UPDATE Boeken
SET Categorie = 'Wiskundige logica'
WHERE Titel = 'Logicaboek';UPDATE Boeken
SET Categorie = 'Geschiedenis'
WHERE Familienaam = 'Braudel' or
Familienaam = 'Bernard' or
Familienaam = 'Bloch';UPDATE Boeken SET Categorie = concat('CATEGORIE: ', Categorie);USE ApDB;
-- oplopend sorteren volgens familienaam
-- ascending
SELECT Voornaam, Familienaam, Titel FROM Boeken
ORDER BY Familienaam ASC, Voornaam, Titel;
-- aflopend sorteren volgens familienaam
-- descending
SELECT Voornaam, Familienaam, Titel FROM Boeken
ORDER BY Familienaam DESC, Voornaam, TitelSELECT SUBSTRING(Familienaam,1,2) FROM Boeken;SELECT SUBSTRING('Hallo',1,2);SELECT 'Ha';SELECT LEFT('Hallo',2);SELECT CONCAT(Voornaam,' ',Familienaam) FROM Boeken;SELECT CONCAT(Voornaam,' ',Familienaam) AS Naam FROM Boeken;SELECT Length(Familienaam) FROM Boeken;SELECT Length('abc');SELECT 1 + Duurtijd FROM Nummers;
SELECT Duurtijd - 1 FROM Nummers;USE ApDB;
SELECT AVG(Leeftijd), Geslacht
FROM Honden
GROUP BY Geslacht;USE ApDB;
SELECT COUNT(*), Geslacht
FROM Honden
GROUP BY Geslacht;USE ApDB;
SELECT Leeftijd
FROM Honden
GROUP BY Geslacht;USE ApDB;
SELECT COUNT(*), Geslacht, Leeftijd
FROM Honden
GROUP BY Geslacht, Leeftijd
ORDER BY Leeftijd, Geslacht;USE ApDB;
SELECT COUNT(*), Leeftijd
FROM Honden
GROUP BY Leeftijd;SELECT TRUE OR NULL;USE ApDB;
SELECT Voornaam, Familienaam, Titel
FROM Boeken
WHERE Familienaam LIKE '%s';USE ApDB;
SELECT Voornaam, Familienaam, Titel, Verschijningsjaar
FROM Boeken
WHERE Titel LIKE '%economie%';USE ApDB;
SELECT Familienaam, Titel FROM Boeken WHERE Familienaam < 'B';USE ApDB;
SELECT Familienaam, Titel FROM Boeken WHERE Familienaam <= 'B';USE ApDB;
INSERT INTO Boeken (Familienaam,Titel,Voornaam,Categorie)
VALUES
('B','Het Boek','Jef','Filosofie');
SELECT Titel, Familienaam FROM Boeken
where Familienaam <= 'B';USE ApDB;
SELECT Familienaam, Titel FROM Boeken where Familienaam <= 'Bz';USE ApDB;
SELECT Familienaam, Titel FROM Boeken where Familienaam < 'C'INSERT INTO Boeken (
Voornaam,
Familienaam,
Titel,
Categorie
)
VALUES
(
'Emile',
'Bréhier',
'Cours de Philosophie',
'Filosofie'
),
(
'Andre',
'Breton',
'Nadja',
'Roman'
);
SELECT Voornaam, Familienaam, Titel FROM Boeken
where Familienaam <= 'Breton';SELECT * FROM Boeken WHERE Familienaam COLLATE utf8mb4_0900_as_cs = 'Breton';SELECT expressie(s) waarin sleutelwoorden, namen en constanten zitten FROM TabelSELECT expression(s) waarin sleutelwoorden, namen en constanten zitten
[FROM Tabel]
[WHERE clause]
[GROUP BY clause]
[HAVING clause]
[ORDER BY clause]USE ApDB;
SELECT AVG(Leeftijd)
FROM Honden
GROUP BY Geslacht
WHERE Geslacht = 'mannelijk';-- een voorbeeld met een gegroepeerde kolom
USE ApDB;
SELECT AVG(Leeftijd)
FROM Honden
GROUP BY Geslacht
HAVING Geslacht = 'mannelijk';-- een voorbeeld met een geaggregeerde waarde
USE ApDB;
SELECT Geslacht
FROM Honden
GROUP BY Geslacht
HAVING AVG(Leeftijd) > 4;-- Gebruik i.p.v. ApDb de naam van jouw databank !!!
USE `ApDb`;
-- MySQL dump 10.13 Distrib 8.0.17, for Linux (x86_64)
--
-- Host: localhost Database: ModernWays
-- ------------------------------------------------------
-- Server version 8.0.17
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `Huisdieren`
--
DROP TABLE IF EXISTS `Huisdieren`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Huisdieren` (
`Naam` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`Leeftijd` smallint(5) unsigned NOT NULL,
`Soort` varchar(50) NOT NULL,
`Baasje` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Huisdieren`
--
LOCK TABLES `Huisdieren` WRITE;
/*!40000 ALTER TABLE `Huisdieren` DISABLE KEYS */;
/*!40000 ALTER TABLE `Huisdieren` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Liedjes`
--
DROP TABLE IF EXISTS `Liedjes`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Liedjes` (
`Titel` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`Artiest` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`Jaar` char(4) DEFAULT NULL,
`Album` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Liedjes`
--
LOCK TABLES `Liedjes` WRITE;
/*!40000 ALTER TABLE `Liedjes` DISABLE KEYS */;
INSERT INTO `Liedjes` VALUES ('John the Revelator','Larkin Poe','2017','Peach'),('Missionary Man','Ghost','2016','Popestar');
/*!40000 ALTER TABLE `Liedjes` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Metingen`
--
DROP TABLE IF EXISTS `Metingen`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Metingen` (
`Tijdstip` datetime NOT NULL,
`Grootte` smallint(5) unsigned NOT NULL,
`Marge` float(3,2) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Metingen`
--
LOCK TABLES `Metingen` WRITE;
/*!40000 ALTER TABLE `Metingen` DISABLE KEYS */;
/*!40000 ALTER TABLE `Metingen` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;
-- Dump completed on 2019-10-13 16:32:53git add --all
git commit -m "Scripts DML"
git pushgit add --all
git commit -m "Scripts DML"
git pushSELECT *
FROM Taken
CROSS JOIN Leden
ORDER BY Taken.Id, Leden.Id;SELECT *
FROM Taken
CROSS JOIN Leden
WHERE Taken.Id = Taken_Id;SELECT *
FROM Taken
INNER JOIN Leden
ON Taken.Id = Taken_Id;USE ApDB;
CREATE TABLE Honden (
Naam VARCHAR(50) NOT NULL,
Leeftijd INT NOT NULL,
Geslacht ENUM('mannelijk','vrouwelijk') -- "er zijn maar twee mogelijkheden"
);
INSERT INTO Honden (Naam,Leeftijd,Geslacht)
VALUES
("Rose",1,"vrouwelijk"),
("Lacy",7,"vrouwelijk"),
("Phoebe",4,"vrouwelijk"),
("Camilla",14,"vrouwelijk"),
("Betsy",7,"vrouwelijk"),
("Lena",8,"vrouwelijk"),
("Ella",8,"vrouwelijk"),
("Samantha",15,"vrouwelijk"),
("Sophia",7,"vrouwelijk"),
("Abby",4,"vrouwelijk"),
("Lily",10,"vrouwelijk"),
("Biscuit",11,"vrouwelijk"),
("Nori",8,"vrouwelijk"),
("Sam",5,"vrouwelijk"),
("Mika",9,"vrouwelijk"),
("Baby",10,"vrouwelijk"),
("Blondie",14,"vrouwelijk"),
("Leia",10,"vrouwelijk"),
("Mackenzie",10,"vrouwelijk"),
("Trixie",11,"vrouwelijk"),
("Hannah",9,"vrouwelijk"),
("Kallie",5,"vrouwelijk"),
("Maya",14,"vrouwelijk"),
("Inez",15,"vrouwelijk"),
("Gemma",8,"vrouwelijk"),
("Priscilla",9,"vrouwelijk"),
("Zoe",8,"vrouwelijk"),
("Camilla",1,"vrouwelijk"),
("Fiona",9,"vrouwelijk"),
("Marley",11,"vrouwelijk"),
("Betsy",12,"vrouwelijk"),
("Bailey",8,"vrouwelijk"),
("Gia",5,"vrouwelijk"),
("Peanut",4,"vrouwelijk"),
("Fern",4,"vrouwelijk"),
("Tootsie",13,"vrouwelijk"),
("Summer",11,"vrouwelijk"),
("Gidget",3,"vrouwelijk"),
("Brandy",1,"vrouwelijk"),
("Peaches",1,"vrouwelijk"),
("Sophie",11,"vrouwelijk"),
("Cookie",14,"vrouwelijk"),
("Ivy",1,"vrouwelijk"),
("Mackenzie",10,"vrouwelijk"),
("Sammie",9,"vrouwelijk"),
("Sandy",8,"vrouwelijk"),
("Callie",12,"vrouwelijk"),
("Samantha",10,"vrouwelijk"),
("Lola",2,"vrouwelijk"),
("Angel",14,"vrouwelijk"),
("Edie",12,"vrouwelijk"),
("Diamond",5,"vrouwelijk"),
("Bonnie",1,"vrouwelijk"),
("Cinnamon",8,"vrouwelijk"),
("Ella",12,"vrouwelijk"),
("Brooklyn",14,"vrouwelijk"),
("Miley",7,"vrouwelijk"),
("Pebbles",5,"vrouwelijk"),
("Hazel",3,"vrouwelijk"),
("Peaches",7,"vrouwelijk"),
("Bean",6,"vrouwelijk"),
("Bianca",10,"vrouwelijk"),
("Brandy",9,"vrouwelijk"),
("Cleo",8,"vrouwelijk"),
("Sam",9,"vrouwelijk"),
("Precious",2,"vrouwelijk"),
("Star",13,"vrouwelijk"),
("Tessa",15,"vrouwelijk"),
("Callie",6,"vrouwelijk"),
("Daisy",15,"vrouwelijk"),
("Darlene",9,"vrouwelijk"),
("Madison",5,"vrouwelijk"),
("Biscuit",4,"vrouwelijk"),
("Lacy",8,"vrouwelijk"),
("Destiny",4,"vrouwelijk"),
("Olivia",6,"vrouwelijk"),
("Allie",15,"vrouwelijk"),
("Khloe",13,"vrouwelijk"),
("Dolly",14,"vrouwelijk"),
("Bonnie",6,"vrouwelijk"),
("Blossom",7,"vrouwelijk"),
("Jenna",14,"vrouwelijk"),
("Violet",12,"vrouwelijk"),
("Bean",13,"vrouwelijk"),
("Anna",12,"vrouwelijk"),
("Betty",12,"vrouwelijk"),
("Destiny",3,"vrouwelijk"),
("Nina",3,"vrouwelijk"),
("Tilly",14,"vrouwelijk"),
("Dana",10,"vrouwelijk"),
("Ruby",14,"vrouwelijk"),
("Fiona",3,"vrouwelijk"),
("Brutus",8,"mannelijk"),
("Nero",5,"mannelijk"),
("Otto",13,"mannelijk"),
("Rascal",9,"mannelijk"),
("Kane",1,"mannelijk"),
("Odie",9,"mannelijk"),
("Ralph",9,"mannelijk"),
("Tank",14,"mannelijk"),
("Taz",2,"mannelijk"),
("Kobe",5,"mannelijk"),
("Dodge",4,"mannelijk"),
("Aries",11,"mannelijk"),
("Ned",11,"mannelijk"),
("Alex",9,"mannelijk"),
("Bo",10,"mannelijk"),
("Eli",5,"mannelijk"),
("Porter",2,"mannelijk"),
("Duke",6,"mannelijk"),
("Carter",13,"mannelijk"),
("Casper",14,"mannelijk"),
("Brutus",2,"mannelijk"),
("Buddy",12,"mannelijk"),
("Barkley",9,"mannelijk"),
("Theo",5,"mannelijk"),
("Maverick",12,"mannelijk"),
("Buddy",9,"mannelijk"),
("Taz",5,"mannelijk"),
("Harvey",11,"mannelijk"),
("Scout",5,"mannelijk"),
("Rudy",13,"mannelijk"),
("Trapper",15,"mannelijk"),
("Buster",10,"mannelijk"),
("Rocco",4,"mannelijk"),
("Vinnie",1,"mannelijk"),
("Murphy",13,"mannelijk"),
("George",9,"mannelijk"),
("Milo",11,"mannelijk"),
("Kobe",2,"mannelijk"),
("AJ",3,"mannelijk"),
("Cash",11,"mannelijk"),
("Eli",6,"mannelijk"),
("Dane",9,"mannelijk"),
("Theo",13,"mannelijk"),
("Cash",7,"mannelijk"),
("Nelson",3,"mannelijk"),
("Luke",10,"mannelijk"),
("Harvey",4,"mannelijk"),
("Riley",6,"mannelijk"),
("Tyson",9,"mannelijk"),
("Gage",5,"mannelijk"),
("Iggy",2,"mannelijk"),
("Marley",7,"mannelijk"),
("Fritz",15,"mannelijk"),
("Bailey",14,"mannelijk"),
("Porter",3,"mannelijk"),
("King",10,"mannelijk"),
("Snoopy",10,"mannelijk"),
("Lewis",15,"mannelijk"),
("Levi",1,"mannelijk"),
("Leo",10,"mannelijk"),
("Vince",2,"mannelijk"),
("Trapper",13,"mannelijk"),
("Kobe",11,"mannelijk"),
("Simba",11,"mannelijk"),
("Zeus",3,"mannelijk"),
("Flash",15,"mannelijk"),
("Watson",6,"mannelijk"),
("Benji",3,"mannelijk"),
("Frankie",15,"mannelijk"),
("Dane",3,"mannelijk"),
("Finn",1,"mannelijk"),
("Coco",8,"mannelijk"),
("Bailey",11,"mannelijk"),
("Storm",11,"mannelijk"),
("Griffin",2,"mannelijk"),
("Zeus",13,"mannelijk"),
("Boomer",15,"mannelijk");USE ApDB;
SELECT COUNT(Naam)
FROM Honden;USE ApDB;
SELECT COUNT(*)
FROM Honden;USE ApDB;
SELECT SUM(Leeftijd)
FROM Honden;USE ApDB;
SELECT SUM(Leeftijd+1)
FROM Honden;USE ApDB;
SELECT MAX(Leeftijd)
FROM Honden;USE ApDB;
SELECT AVG(Leeftijd)
FROM Honden;USE ApDB;
SELECT COUNT(*), Naam
FROM Honden;GenreINSERT query het gedeelte VALUES (...) vervangen door een subquery waarvan de resultaten overeenstemmen met de values die je zou invullen. Met andere woorden: INSERT INTO EenTabel (IngevuldeKolom1, IngevuldeKolom2) (select KolomWaarde1, KolomWaarde2 from EenAndereTabel); Noem je script aptunes__0025.sql.aptunes__0043.sql

RIGHT [OUTER] JOIN: met deze clausule kunnen we alle records ophalen uit de tabel die aan de rechterkant van de JOIN staat gespecificeerd, dus ook de rijen uit de rechtse tabel die niet aan de join voorwaarde voldoen worden ook in het resultaat weergegeven.drop database if exists `ApDB`;
CREATE DATABASE IF NOT EXISTS `ApDB` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `ApDB`;
-- MySQL dump 10.13 Distrib 8.0.19, for Linux (x86_64)
--
-- Host: localhost Database: ModernWays
-- ------------------------------------------------------
-- Server version 8.0.17
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `Boeken`
--
DROP TABLE IF EXISTS `Boeken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Boeken` (
`Titel` varchar(200) DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
`Personen_Id` int(11) DEFAULT NULL,
PRIMARY KEY (`Id`),
KEY `fk_Boeken_Personen` (`Personen_Id`),
CONSTRAINT `fk_Boeken_Personen` FOREIGN KEY (`Personen_Id`) REFERENCES `Personen` (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Boeken`
--
LOCK TABLES `Boeken` WRITE;
/*!40000 ALTER TABLE `Boeken` DISABLE KEYS */;
INSERT INTO `Boeken` VALUES ('Norwegian Wood',1,10),('Kafka on the Shore',2,10),('American Gods',3,16),('The Ocean at the End of the Lane',4,16),('Pet Sematary',5,17),('Good Omens',6,18),('The Talisman',7,17);
/*!40000 ALTER TABLE `Boeken` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Personen`
--
DROP TABLE IF EXISTS `Personen`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Personen` (
`Voornaam` varchar(25) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Familienaam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
`AanspreekTitel` varchar(20) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Straat` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Huisnummer` varchar(5) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Stad` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Commentaar` varchar(1000) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Biografie` text CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Personen`
--
LOCK TABLES `Personen` WRITE;
/*!40000 ALTER TABLE `Personen` DISABLE KEYS */;
INSERT INTO `Personen` VALUES ('Samuel','Ijsseling',1,NULL,NULL,NULL,NULL,NULL,NULL),('Jacob','Van Sluis',2,NULL,NULL,NULL,NULL,NULL,NULL),('Emile','Benveniste',3,NULL,NULL,NULL,NULL,NULL,NULL),('Evert W.','Beth',4,NULL,NULL,NULL,NULL,NULL,NULL),('Rémy','Bernard',5,NULL,NULL,NULL,NULL,NULL,NULL),('Robert','Bly',6,NULL,NULL,NULL,NULL,NULL,NULL),('timothy','gowers',7,NULL,NULL,NULL,NULL,NULL,NULL),(NULL,'?',8,NULL,NULL,NULL,NULL,NULL,NULL),(NULL,'Ovidius',9,NULL,NULL,NULL,NULL,NULL,NULL),('Haruki','Murakami',10,NULL,NULL,NULL,NULL,NULL,NULL),('David','Mitchell',11,NULL,NULL,NULL,NULL,NULL,NULL),('Nick','Harkaway',12,NULL,NULL,NULL,NULL,NULL,NULL),('Thomas','Ligotti',13,NULL,NULL,NULL,NULL,NULL,NULL),('Neil','Gaiman',16,NULL,NULL,NULL,NULL,NULL,NULL),('Stephen','King',17,NULL,NULL,NULL,NULL,NULL,NULL),('Terry','Pratchett',18,NULL,NULL,NULL,NULL,NULL,NULL),('Peter','Straub',19,NULL,NULL,NULL,NULL,NULL,NULL);
/*!40000 ALTER TABLE `Personen` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;

CREATE VIEW viewnaam
AS
SELECT ??? -- hier kan vanalles komen, maar er wordt een resultatenset getoondSELECT Leden.voornaam, Taken.omschrijving
FROM Taken
INNER JOIN Leden
ON Leden.Id = Taken.Leden_Id;CREATE VIEW TakenLeden
AS
SELECT Leden.voornaam, Taken.omschrijving
FROM Taken
INNER JOIN Leden ON Leden.Id = Taken.Leden_Id;SELECT *
FROM TakenLeden;USE ApDB;
RENAME TABLE Takenleden
TO TakenLeden_Updated;SUMAVGCOUNTUSE ApDB;
UPDATE TakenLeden
SET Omschrijving = 'frisdrank voorzien'
WHERE Voornaam = 'Yannick';SELECT table_name, is_updatable
FROM information_schema.views
WHERE table_schema = 'ApDB';

DROP DATABASE IF EXISTS `ApDB`;
CREATE DATABASE IF NOT EXISTS `ApDB` /*!40100 DEFAULT CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci */ /*!80016 DEFAULT ENCRYPTION='N' */;
USE `ApDB`;
-- MySQL dump 10.13 Distrib 8.0.19, for Linux (x86_64)
--
-- Host: localhost Database: ApDB
-- ------------------------------------------------------
-- Server version 8.0.17
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
/*!50503 SET NAMES utf8 */;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `Boeken`
--
DROP TABLE IF EXISTS `Boeken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Boeken` (
`Titel` varchar(200) DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Boeken`
--
LOCK TABLES `Boeken` WRITE;
/*!40000 ALTER TABLE `Boeken` DISABLE KEYS */;
INSERT INTO `Boeken` VALUES ('Norwegian Wood',1),('Kafka on the Shore',2),('American Gods',3),('The Ocean at the End of the Lane',4),('Pet Sematary',5),('Good Omens',6),('The Talisman',7);
/*!40000 ALTER TABLE `Boeken` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Personen`
--
DROP TABLE IF EXISTS `Personen`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Personen` (
`Voornaam` varchar(25) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Familienaam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Personen`
--
LOCK TABLES `Personen` WRITE;
/*!40000 ALTER TABLE `Personen` DISABLE KEYS */;
INSERT INTO `Personen` VALUES ('Samuel','Ijsseling',1),('Jacob','Van Sluis',2),('Emile','Benveniste',3),('Evert W.','Beth',4),('Rémy','Bernard',5),('Robert','Bly',6),('timothy','gowers',7),(NULL,'?',8),(NULL,'Ovidius',9),('Haruki','Murakami',10),('David','Mitchell',11),('Nick','Harkaway',12),('Thomas','Ligotti',13),('Neil','Gaiman',16),('Stephen','King',17),('Terry','Pratchett',18),('Peter','Straub',19);
/*!40000 ALTER TABLE `Personen` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Publicaties`
--
DROP TABLE IF EXISTS `Publicaties`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Publicaties` (
`Boeken_Id` int(11) NOT NULL,
`Personen_Id` int(11) NOT NULL,
KEY `fk_Publicaties_Boeken` (`Boeken_Id`),
KEY `fk_Publicaties_Personen` (`Personen_Id`),
CONSTRAINT `fk_Publicaties_Boeken` FOREIGN KEY (`Boeken_Id`) REFERENCES `Boeken` (`Id`),
CONSTRAINT `fk_Publicaties_Personen` FOREIGN KEY (`Personen_Id`) REFERENCES `Personen` (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Publicaties`
--
LOCK TABLES `Publicaties` WRITE;
/*!40000 ALTER TABLE `Publicaties` DISABLE KEYS */;
INSERT INTO `Publicaties` VALUES (1,10),(2,10),(3,16),(4,16),(5,17),(6,16),(6,18),(7,17),(7,19);
/*!40000 ALTER TABLE `Publicaties` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Reviews`
--
DROP TABLE IF EXISTS `Reviews`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
/*!50503 SET character_set_client = utf8mb4 */;
CREATE TABLE `Reviews` (
`Boeken_Id` int(11) NOT NULL,
`Rating` tinyint(4) NOT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Reviews`
--
LOCK TABLES `Reviews` WRITE;
/*!40000 ALTER TABLE `Reviews` DISABLE KEYS */;
INSERT INTO `Reviews` VALUES (1,4),(1,5),(1,5),(2,5),(3,3),(3,4),(3,4),(3,5),(4,4),(5,3),(6,4),(7,3);
/*!40000 ALTER TABLE `Reviews` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;















USE ApDB;
SELECT * FROM Honden
WHERE Naam IN ('Bailey','Cookie','Lola','Iggy','Snoopy','Leo')USE ApDB;
SELECT * FROM Honden
WHERE Naam COLLATE utf8mb4_0900_as_cs IN ('Bailey','Cookie','Lola','Iggy','Snoopy','Leo')USE ApDB;
SELECT MAX(Leeftijd)
FROM Honden
GROUP BY Geslacht
HAVING MAX(Leeftijd) IN (13,15);SELECT 5 in (3,7,9);Entity Relationschip Model
use ApDB;
set sql_safe_updates = 0;
-- "Nummers" betekent hier "Liedjes"
update Nummers inner join Artiesten
on Artiesten.Naam = Nummers.Artiest
set Nummers.Artiesten_Id = Artiesten.Id;
set sql_safe_updates = 1;


select * from Nummers inner join Artiesten
on Artiesten.Naam = Nummers.Artiest; -- niet op ID!Dit is geen te kennen leerstof.
Informatisering van een bank
DROP VIEW IF EXISTS viewnaam;DROP VIEW IF EXISTS TakenLeden;DROP INDEX index_name ON table_name;DROP INDEX `PRIMARY` ON table_name;SELECT Games_Id, Platformen_Id, Titel
FROM Releases
INNER JOIN Games
ON Games_Id = Games.Id;SELECT Titel, Naam
FROM Releases
INNER JOIN Games
ON Games_Id = Games.Id
INNER JOIN Platformen
ON Platformen_Id = Platformen.Id;CREATE INDEX Column1Column2Index on TableName(Column1,Column2);column_name(length)-- mogen meerdere colum_names zijn, gescheiden door komma
-- length is optioneel
CREATE TABLE Table_name(
column_list,
INDEX(column_name(length))
);-- zelfde opmerking als boven
-- je mag een index op meerdere kolommen samen maken
CREATE INDEX index_name
ON table_name(column_name(length));USE ApDB;
SELECT *
FROM Taken
WHERE Omschrijving LIKE 'aardappel%';USE ApDB;
EXPLAIN SELECT *
FROM Taken
WHERE Omschrijving LIKE 'aardappel%';select count(distinct Omschrijving)
from Taken;select max(length(Omschrijving)) from Taken;select count(distinct left(Omschrijving,20))
from Taken;USE ApDB;
CREATE INDEX OmschrijvingIdx
ON Taken(Omschrijving(20));select Voornaam, Familienaam
from Werknemers
where Kantoornummer in (select Kantoornummer from Kantoorruimtes where Beamer);create table Customers (
Id int auto_increment primary key,
Name varchar(100) not null
);
create table DeliveryAddresses (
Id int auto_increment primary key,
Street varchar(100) not null,
HouseNumber int not null,
Customers_Id int not null,
constraint fk_DeliveryAddresses_Customers
foreign key (Customers_Id)
references Customers(Id)
);
insert into Customers (Name)
values
('Edelgard'),
('Dimitri'),
('Claude');
insert into DeliveryAddresses (Street, HouseNumber, Customers_Id)
values
('Adrestia street', 1, 1),
('Faerghus avenue', 100, 2);-- eerdere code
REFERENCES SomeTable(Column1) -- vaak 1 kolom, kan in principe wel meer zijn
[ON DELETE action]-- eerdere code
REFERENCES SomeTable(Column1) -- vaak 1 kolom, kan in principe wel meer zijn
[ON UPDATE action]select avg(Leeftijd) from Personen;select Voornaam, Familienaam
from Personen
where Leeftijd >= (select max(Leeftijd) from Personen) - 10;select Voornaam, Familienaam
from Personen
where Leeftijd between (select avg(Leeftijd) from Personen) - 5 AND (select avg(Leeftijd) from Personen) + 5;select Naam
from Studenten
where Cijfer < (select avg(Cijfer) from Studenten)delete from Personen
where Leeftijd = (select min(Leeftijd) from Personen);set @mySessionVariable = (select min(Leeftijd) from Personen);set @minimumLeeftijd = (select min(Leeftijd) from Personen);
delete from Personen
where Leeftijd = @minimumLeeftijd;select Voornaam, Familienaam
from Personen
where Voornaam in (select distinct Familienaam from Personen);select min(avg(Leeftijd))
from Personen
group by Voornaam;-- tijdelijke tabel maken
drop temporary table if exists gemiddeldeLeeftijdPerNaam;
create temporary table gemiddeldeLeeftijdPerNaam (
Naam varchar(200) not null,
Leeftijd int not null
);
-- tijdelijke tabel invullen
insert into gemiddeldeLeeftijdPerNaam
(select Voornaam, avg(Leeftijd) from Personen group by Personen.Voornaam);
-- het resultaat aflezen
select min(Leeftijd) from gemiddeldeLeeftijdPerNaam;SELECT <kolommen uit A of uit B>
FROM A
RIGHT JOIN B
-- opnieuw: schrijfwijze hangt af van waar foreign key staat
ON A.B_Id = B.IdSELECT Personen.Voornaam, Personen.Familienaam,
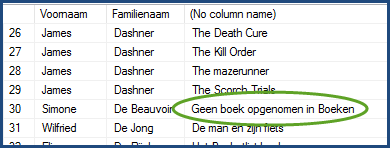
COALESCE (Boeken.Titel, 'Geen boek opgenomen in Boeken')
FROM Boeken
LEFT JOIN Personen on Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;-- net als tevoren kan de code wat variëren
-- de foreign key staat hier in de rechtertabel
-- hij kan (mits aanpassingen) ook in de linkertabel
SELECT <kolommen uit A of uit B>
FROM A
LEFT JOIN B
ON A.Id = B.A_Id
UNION ALL -- plaats de resultaten onder elkaar -> maak de kolommen expliciet! geen *
SELECT <select_list>
FROM A
RIGHT JOIN B
ON A.B_Id = B.Id
WHERE A.B_Id IS NULLCREATE UNIQUE INDEX index_name
ON table_name(index_column_1,index_column_2,...);
SELECT <select_list>
FROM A
LEFT JOIN B
-- ook hier kan het zijn dat de linkertabel de primary key bevat
ON A.B_Id = B.Id
WHERE A.B_Id IS NULL
-- LET OP:
-- hier moet je altijd de foreign key kolom gebruiken
-- een primary key kan immers nooit NULL zijnSELECT <select_list>
FROM A
RIGHT JOIN B
-- ook hier kan het zijn dat de linkertabel de primary key bevat
ON A.B_Id = B.Id
WHERE A.B_Id IS NULL
-- LET OP:
-- hier moet je altijd de foreign key kolom gebruiken
-- een primary key kan immers nooit NULL zijnSELECT Personen.Voornaam, Personen.Familienaam,
COALESCE (Boeken.Titel, 'Geen boek opgenomen in Boeken')
FROM Personen
LEFT JOIN Boeken ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;


SELECT <kolommen uit A of uit B>
FROM A
LEFT JOIN B
-- hier veronderstellen we dat de vreemde sleutel in B staat
ON A.Id = B.A_Id
-- alternatief met vreemde sleutel in A:
-- ON A.B_Id = B.IdSELECT Personen.Voornaam, Personen.Familienaam,
Boeken.Titel
FROM Personen
LEFT JOIN Boeken ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;SELECT Personen.Voornaam, Personen.Familienaam,
COALESCE (Boeken.Titel, 'Geen boek opgenomen in Boeken')
FROM Boeken
RIGHT JOIN Personen ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;SELECT Personen.Voornaam, Personen.Familienaam,
COALESCE (Boeken.Titel, 'Geen boek opgenomen in Boeken')
AS 'Titel van het boek'
FROM Boeken
RIGHT JOIN Personen ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;-- MySQL dump 10.13 Distrib 8.0.16, for Linux (x86_64)
--
-- Host: localhost Database: ApDB
-- ------------------------------------------------------
-- Server version 8.0.16
/*!40101 SET @OLD_CHARACTER_SET_CLIENT=@@CHARACTER_SET_CLIENT */;
/*!40101 SET @OLD_CHARACTER_SET_RESULTS=@@CHARACTER_SET_RESULTS */;
/*!40101 SET @OLD_COLLATION_CONNECTION=@@COLLATION_CONNECTION */;
SET NAMES utf8mb4 ;
/*!40103 SET @OLD_TIME_ZONE=@@TIME_ZONE */;
/*!40103 SET TIME_ZONE='+00:00' */;
/*!40014 SET @OLD_UNIQUE_CHECKS=@@UNIQUE_CHECKS, UNIQUE_CHECKS=0 */;
/*!40014 SET @OLD_FOREIGN_KEY_CHECKS=@@FOREIGN_KEY_CHECKS, FOREIGN_KEY_CHECKS=0 */;
/*!40101 SET @OLD_SQL_MODE=@@SQL_MODE, SQL_MODE='NO_AUTO_VALUE_ON_ZERO' */;
/*!40111 SET @OLD_SQL_NOTES=@@SQL_NOTES, SQL_NOTES=0 */;
--
-- Table structure for table `Auteurs`
--
DROP DATABASE if exists ApDB;
CREATE DATABASE ApDB;
USE ApDB;
DROP TABLE IF EXISTS `Auteurs`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Auteurs` (
`Voornaam` varchar(25) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Familienaam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=20 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Auteurs`
--
LOCK TABLES `Auteurs` WRITE;
/*!40000 ALTER TABLE `Auteurs` DISABLE KEYS */;
INSERT INTO `Auteurs` VALUES ('Samuel','Ijsseling',1),('Jacob','Van Sluis',2),('Emile','Benveniste',3),('Evert W.','Beth',4),('R├®my','Bernard',5),('Robert','Bly',6),('timothy','gowers',7),(NULL,'?',8),(NULL,'Ovidius',9),('Haruki','Murakami',10),('David','Mitchell',11),('Nick','Harkaway',12),('Thomas','Ligotti',13),('Neil','Gaiman',16),('Stephen','King',17),('Terry','Pratchett',18),('Peter','Straub',19);
/*!40000 ALTER TABLE `Auteurs` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Boeken`
--
DROP TABLE IF EXISTS `Boeken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Boeken` (
`Titel` varchar(200) DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=8 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Boeken`
--
LOCK TABLES `Boeken` WRITE;
/*!40000 ALTER TABLE `Boeken` DISABLE KEYS */;
INSERT INTO `Boeken` VALUES ('Norwegian Wood',1),('Kafka on the Shore',2),('American Gods',3),('The Ocean at the End of the Lane',4),('Pet Sematary',5),('Good Omens',6),('The Talisman',7);
/*!40000 ALTER TABLE `Boeken` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `BoekenNaarAuteurs`
--
DROP TABLE IF EXISTS `BoekenNaarAuteurs`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `BoekenNaarAuteurs` (
`Boeken_Id` int(11) NOT NULL,
`Auteurs_Id` int(11) NOT NULL,
KEY `fk_BoekenNaarAuteurs_Boeken` (`Boeken_Id`),
KEY `fk_BoekenNaarAuteurs_Auteurs` (`Auteurs_Id`),
CONSTRAINT `fk_BoekenNaarAuteurs_Auteurs` FOREIGN KEY (`Auteurs_Id`) REFERENCES `Auteurs` (`Id`),
CONSTRAINT `fk_BoekenNaarAuteurs_Boeken` FOREIGN KEY (`Boeken_Id`) REFERENCES `Boeken` (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `BoekenNaarAuteurs`
--
LOCK TABLES `BoekenNaarAuteurs` WRITE;
/*!40000 ALTER TABLE `BoekenNaarAuteurs` DISABLE KEYS */;
/*!40000 ALTER TABLE `BoekenNaarAuteurs` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Games`
--
DROP TABLE IF EXISTS `Games`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Games` (
`Titel` varchar(100) NOT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Games`
--
LOCK TABLES `Games` WRITE;
/*!40000 ALTER TABLE `Games` DISABLE KEYS */;
INSERT INTO `Games` VALUES ('Anthem',1),('Sekiro: Shadows Die Twice',2),('Devil May Cry 5',3),('Mega Man 11',4),('Oregon Trail',5);
/*!40000 ALTER TABLE `Games` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Leden`
--
DROP TABLE IF EXISTS `Leden`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Leden` (
`Voornaam` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Leden`
--
LOCK TABLES `Leden` WRITE;
/*!40000 ALTER TABLE `Leden` DISABLE KEYS */;
INSERT INTO `Leden` VALUES ('Yannick',1),('Bavo',2),('Max',3),('Herve',4);
/*!40000 ALTER TABLE `Leden` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Platformen`
--
DROP TABLE IF EXISTS `Platformen`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Platformen` (
`Naam` varchar(20) NOT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Platformen`
--
LOCK TABLES `Platformen` WRITE;
/*!40000 ALTER TABLE `Platformen` DISABLE KEYS */;
INSERT INTO `Platformen` VALUES ('PS4',1),('Xbox One',2),('Windows',3),('Nintendo Switch',4),('Master System',5);
/*!40000 ALTER TABLE `Platformen` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Postcodes`
--
DROP TABLE IF EXISTS `Postcodes`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Postcodes` (
`Code` char(4) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL,
`Plaats` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`Localite` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`Provincie` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL,
`Province` varchar(120) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Postcodes`
--
LOCK TABLES `Postcodes` WRITE;
/*!40000 ALTER TABLE `Postcodes` DISABLE KEYS */;
INSERT INTO `Postcodes` VALUES ('2800','Mechelen','Malines','Antwerpen','Anvers'),('3000','Leuven','Louvain','Vlaams Brabant','Brabant Flamand');
/*!40000 ALTER TABLE `Postcodes` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Releases`
--
DROP TABLE IF EXISTS `Releases`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Releases` (
`Games_Id` int(11) NOT NULL,
`Platformen_Id` int(11) NOT NULL,
KEY `fk_Releases_Games` (`Games_Id`),
KEY `fk_Releases_Platformen` (`Platformen_Id`),
CONSTRAINT `fk_Releases_Games` FOREIGN KEY (`Games_Id`) REFERENCES `Games` (`Id`),
CONSTRAINT `fk_Releases_Platformen` FOREIGN KEY (`Platformen_Id`) REFERENCES `Platformen` (`Id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Releases`
--
LOCK TABLES `Releases` WRITE;
/*!40000 ALTER TABLE `Releases` DISABLE KEYS */;
INSERT INTO `Releases` VALUES (1,1),(1,2),(1,3),(2,1),(2,2),(2,3),(3,1),(3,2),(4,1),(4,2),(4,3),(4,4);
/*!40000 ALTER TABLE `Releases` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Taken`
--
DROP TABLE IF EXISTS `Taken`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Taken` (
`Omschrijving` varchar(50) CHARACTER SET utf8mb4 COLLATE utf8mb4_general_ci NOT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
`Leden_Id` int(11),
PRIMARY KEY (`Id`),
KEY `fk_Taken_Leden` (`Leden_Id`),
CONSTRAINT `fk_Taken_Leden` FOREIGN KEY (`Leden_Id`) REFERENCES `Leden` (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Taken`
--
LOCK TABLES `Taken` WRITE;
/*!40000 ALTER TABLE `Taken` DISABLE KEYS */;
INSERT INTO `Taken` VALUES ('bestek voorzien',1,2),('frisdrank meebrengen',2,1),('aardappelsla maken',3,3),('papieren bordjes meebrengen',4,null);
/*!40000 ALTER TABLE `Taken` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Tweets`
--
DROP TABLE IF EXISTS `Tweets`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Tweets` (
`Bericht` varchar(144) DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
`Users_Id` int(11) DEFAULT NULL,
PRIMARY KEY (`Id`),
KEY `fk_Tweets_Users` (`Users_Id`),
CONSTRAINT `fk_Tweets_Users` FOREIGN KEY (`Users_Id`) REFERENCES `Users` (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Tweets`
--
LOCK TABLES `Tweets` WRITE;
/*!40000 ALTER TABLE `Tweets` DISABLE KEYS */;
INSERT INTO `Tweets` VALUES ('Don\'t forget -- Nintendo Labo: VR Kit launches 12/04!',1,1),('Splat it out in the #Splatoon2 EU Community Cup 5 this Sunday!',2,1),('Crikey! Keep an eye out for cardboard crocs and other crafty wildlife on this jungle train ride! #Yoshi',3,1),('You had a lot to say about #MetroExodus. Check out our favorite 5-word reviews.',4,2),('It\'s a perfect day for some mayhem.',5,2),('Drift all over N. Sanity Beach and beyond in Crash Team Racing Nitro-Fueled.',6,2);
/*!40000 ALTER TABLE `Tweets` ENABLE KEYS */;
UNLOCK TABLES;
--
-- Table structure for table `Users`
--
DROP TABLE IF EXISTS `Users`;
/*!40101 SET @saved_cs_client = @@character_set_client */;
SET character_set_client = utf8mb4 ;
CREATE TABLE `Users` (
`Handle` varchar(144) DEFAULT NULL,
`Id` int(11) NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`Id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
/*!40101 SET character_set_client = @saved_cs_client */;
--
-- Dumping data for table `Users`
--
LOCK TABLES `Users` WRITE;
/*!40000 ALTER TABLE `Users` DISABLE KEYS */;
INSERT INTO `Users` VALUES ('NintendoEurope',1),('Xbox',2);
/*!40000 ALTER TABLE `Users` ENABLE KEYS */;
UNLOCK TABLES;
/*!40103 SET TIME_ZONE=@OLD_TIME_ZONE */;
/*!40101 SET SQL_MODE=@OLD_SQL_MODE */;
/*!40014 SET FOREIGN_KEY_CHECKS=@OLD_FOREIGN_KEY_CHECKS */;
/*!40014 SET UNIQUE_CHECKS=@OLD_UNIQUE_CHECKS */;
/*!40101 SET CHARACTER_SET_CLIENT=@OLD_CHARACTER_SET_CLIENT */;
/*!40101 SET CHARACTER_SET_RESULTS=@OLD_CHARACTER_SET_RESULTS */;
/*!40101 SET COLLATION_CONNECTION=@OLD_COLLATION_CONNECTION */;
/*!40111 SET SQL_NOTES=@OLD_SQL_NOTES */;USE ApDB;
ALTER TABLE Releases
add Datum DATE;USE ApDB;
UPDATE Releases, Games
SET Datum = '2019-02-22'
WHERE Games.Titel = 'Anthem' AND Releases.Games_Id = Games.Id;
UPDATE Releases, Games
SET Datum = '2019-03-22'
WHERE Games.Titel = 'Sekiro: Shadows Die Twice' AND Releases.Games_Id = Games.Id;
UPDATE Releases, Games
SET Datum = '2019-03-08'
WHERE Games.Titel = 'Devil May Cry 5' AND Releases.Games_Id = Games.Id;
UPDATE Releases, Games
SET Datum = '2018-10-02'
WHERE Games.Titel = 'Mega Man 11' AND Releases.Games_Id = Games.Id;SELECT Games.Titel, Platformen.Naam
FROM Releases
INNER JOIN Platformen ON Releases.Platformen_Id = Platformen.Id
INNER JOIN Games ON Releases.Games_Id = Games.Id-- dit is niet de enige mogelijkheid
SELECT <kolommen uit A of uit B>
FROM A
INNER JOIN B ON A.Id = B.A_Id
-- alternatief waarbij je de volgorde wisselt
-- dit mag, want = betekent gewoon "is gelijk aan"
-- 2+2 = 4 betekent hetzelfde als 4 = 2+2
-- INNER JOIN B ON B.A_Id = A.Id
-- alternatief, als A de foreign key bevat:
-- INNER JOIN B ON A.B_Id = B.Id
-- ook hier kan je de volgorde nog eens omwisselenSELECT Personen.Voornaam, Personen.Familienaam,
Boeken.Titel
FROM Boeken
INNER JOIN Personen ON Boeken.Personen_Id = Personen.Id;SELECT Personen.Voornaam, Personen.Familienaam,
Boeken.Titel
FROM Personen
INNER JOIN Boeken ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Voornaam, Personen.Familienaam, Boeken.Titel;INSERT INTO Personen (
Voornaam,
Familienaam,
AanspreekTitel,
Straat,
Huisnummer,
Stad,
Commentaar,
Biografie
)
VALUES
(
'Simone',
'De Beauvoir',
'Mevrouw',
'Rue Charles De Gaulle',
'38',
'Paris',
'Feministe',
'Compagnon van Jean-Paul Sartre'
);SELECT * FROM Personen
ORDER BY Familienaam, Voornaam;SELECT Personen.Voornaam, Personen.Familienaam,
Boeken.Titel
FROM Personen
INNER JOIN Boeken ON Boeken.Personen_Id = Personen.Id
ORDER BY Personen.Familienaam, Personen.Voornaam, Boeken.Titel;CREATE TABLE table_name(
//...
UNIQUE KEY(index_column_1,index_column_2,...)
);CREATE TABLE table_name(
//...
ColName VARCHAR(100) UNIQUE
);CREATE TABLE IF NOT EXISTS People (
id INT AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(50) NOT NULL,
last_name VARCHAR(50) NOT NULL,
mail VARCHAR(50) NOT NULL,
UNIQUE KEY index_unique_mail (mail)
);SHOW INDEXES FROM People;INSERT INTO People(first_name,last_name,mail)
VALUES
('John','Doe','john.doe@modernways.be'),
('Jane','Doe','jane.doe@modernways.be'),
('John','Roe','john.roe@modernways.be'),
('Jane','Roe','jane.roe@modernways.be')
;INSERT INTO People(first_name,last_name,mail)
VALUES ('Jef','Doe','john.doe@modernways.be');